2026 Python 计算生态五月推荐榜 第99期

5月10日 · Python123 2040 人阅读
 |
看见更大的世界,遇见更好的自己
See a better world to meet better for ourselves.
随着大语言模型、智能体系统和多模态应用快速普及,AI 已经从“模型训练”阶段大步迈入“真实生产环境部署”阶段。然而,模型能力越强,其暴露出的安全风险也越复杂:提示注入、越狱攻击、敏感信息泄露、恶意工具调用、模型输出失控、训练数据隐私暴露,以及 RAG 场景下的文档污染和上下文投毒,正在成为 AI 应用落地必须直面的核心挑战。过去人们更多关注模型“能不能用”,而今天,行业更关心的是模型“是否可控、可信、可防护”。
在 2026 年 5 月,围绕大模型安全的开源生态已经初具规模。从越狱测试、提示注入检测、输入输出过滤,到隐私脱敏、风险评估、策略护栏与 AI 红队演练,开发者已经可以借助一批成熟的 Python 工具,为模型系统建立起更完整的安全防线。为了帮助开发者理解并掌握这一方向,我们特别推荐 10 款围绕“模型安全”构建的核心 Python 第三方库和相关框架。
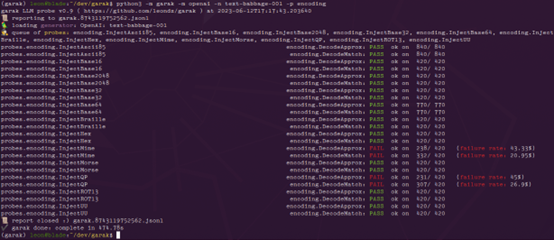
garak
在大模型安全测试领域,garak 已经成为最具代表性的开源工具之一。它专注于对 LLM 进行自动化漏洞探测与红队评估,能够系统性测试模型在越狱、幻觉、有害内容生成、提示注入和策略绕过等方面的风险表现。对于希望像“安全扫描 Web 服务”那样系统扫描大模型行为边界的开发者来说,garak 提供了非常标准且工程化的测试框架,是构建模型安全基线时的首选工具。
https://github.com/NVIDIA/garak
PyRIT
PyRIT 是 Microsoft 推出的生成式 AI 红队自动化框架,专门面向 LLM 应用的安全攻击模拟与风险识别。它能够通过多轮对话策略、攻击模板和自动化编排,对目标模型持续施压,测试其在真实攻击场景中的鲁棒性。相比简单的单轮 prompt 测试,PyRIT 更贴近现实中的攻击过程,尤其适合评估企业级 AI 助手、Copilot 系统和智能代理的防御强度,是 AI 安全工程中非常重要的实战型工具。
https://github.com/microsoft/PyRIT
guardrails-ai
当模型开始广泛承担问答、生成、决策和结构化输出任务后,如何让它“按规则说话”就成了关键问题。guardrails-ai 提供了一套面向 LLM 输出约束、验证和纠偏的护栏机制,开发者可以利用 Python 为模型定义格式、质量、安全和业务规则,并在输出不符合要求时自动重试、修复或阻断。它不是简单地过滤内容,而是在应用层为大模型加上一层可靠的控制边界,是提升模型可控性的重要基础设施。
https://github.com/guardrails-ai/guardrails
llm-guard
如果说 guardrails-ai 偏向“规则控制”,那么 llm-guard 则更强调“输入输出安全防护”。它聚焦于提示注入检测、敏感信息过滤、有害内容检查和输出安全审计,帮助开发者在用户输入进入模型之前、以及模型响应返回用户之前,构建双向安全检查链路。对于构建面向外部用户开放的聊天机器人、企业知识问答系统或 AI 代理应用而言,llm-guard 是极具实用价值的一道安全网。
https://github.com/protectai/llm-guard
Presidio
在 AI 应用中,隐私风险往往并不来自模型本身,而来自输入和输出中夹杂的大量个人敏感信息。Presidio 是 Microsoft 开源的敏感信息识别与脱敏框架,能够识别文本中的姓名、手机号、身份证号、邮箱、地址等隐私数据,并对其进行屏蔽、替换或匿名化处理。对于需要接入真实用户数据、企业文档和客服对话记录的大模型系统而言,Presidio 是构建隐私保护能力最成熟、最稳妥的 Python 工具之一。
https://github.com/microsoft/presidio
LangKit
随着 LLM 应用进入生产环境,模型安全已经不只是“上线前测一测”,更需要“上线后持续监控”。LangKit 是一个面向 LLM 和 NLP 系统的质量分析与风险检测工具包,可以用于识别数据漂移、异常输入、主题偏移、毒性风险和输出异常等问题。它非常适合部署在模型观测与评估链路中,帮助团队从离线测试走向在线监控,把模型安全从一次性工作升级为持续治理能力。
https://github.com/whylabs/langkit
Rebuff
提示注入已经成为 RAG 和 Agent 系统中最具代表性的攻击方式之一,尤其是在模型需要读取外部文档、网页内容或第三方工具返回结果时,恶意指令极易“混进上下文”。Rebuff 就是围绕这一问题诞生的防御工具。它专注于检测和抵御 prompt injection 攻击,通过策略分析与防御机制帮助开发者过滤高风险输入、降低模型被上下文操控的概率。对于文档问答、网页代理和工具调用类应用,Rebuff 提供了很强的针对性价值。
https://github.com/protectai/rebuff
Pydantic
Pydantic 并不是专门为模型安全设计的工具,但它在今天的 LLM 安全工程中扮演着极其重要的角色。很多模型风险并不来自“有害内容”,而来自输出结构不稳定、字段错乱、类型异常,进而导致工具误调用、数据库误写入或业务逻辑失控。Pydantic 通过严格的数据模型定义、类型校验和解析机制,让开发者能够把模型输出约束在确定的结构边界内。对于 Agent、函数调用和结构化生成场景,它几乎是实现“安全可控输出”的标准组件。
https://github.com/pydantic/pydantic
Adversarial Robustness Toolbox
当模型安全从大语言模型延伸到图像、语音和传统机器学习系统时,对抗样本攻击与鲁棒性评估仍然是不可忽视的重要主题。IBM 开源的 Adversarial Robustness Toolbox(ART)提供了丰富的攻击、防御、检测和评估算法,可用于测试模型在对抗扰动、数据投毒和规避攻击面前的稳定性。对于关注更广义“AI 模型安全”的开发者而言,ART 是连接传统机器学习安全与生成式 AI 安全的重要桥梁。
https://github.com/Trusted-AI/adversarial-robustness-toolbox
TextAttack
在自然语言处理安全领域,TextAttack 是极具代表性的对抗攻击与鲁棒性评估框架。它最早服务于文本分类、情感分析和 NLP 模型鲁棒性测试,但在今天依然对 LLM 安全研究具有重要参考价值。开发者可以借助它构造语义保持但扰动形式不同的恶意输入,评估模型在改写攻击、对抗样本和鲁棒性场景中的表现。对于研究语言模型“看似理解、实则脆弱”的安全边界,TextAttack 依然是一把非常锋利的工具。
https://github.com/QData/TextAttack
Python3Turtle
