start
前面我们讲解了一些基础的爬虫,但在一些爬虫中,有些网站是要求我们需要登录才可以访问从而提取数据的,因此我们在构造爬虫时,需要用到登录手段,我们先来个简单的,以 selnium 登录为例,教大家登录
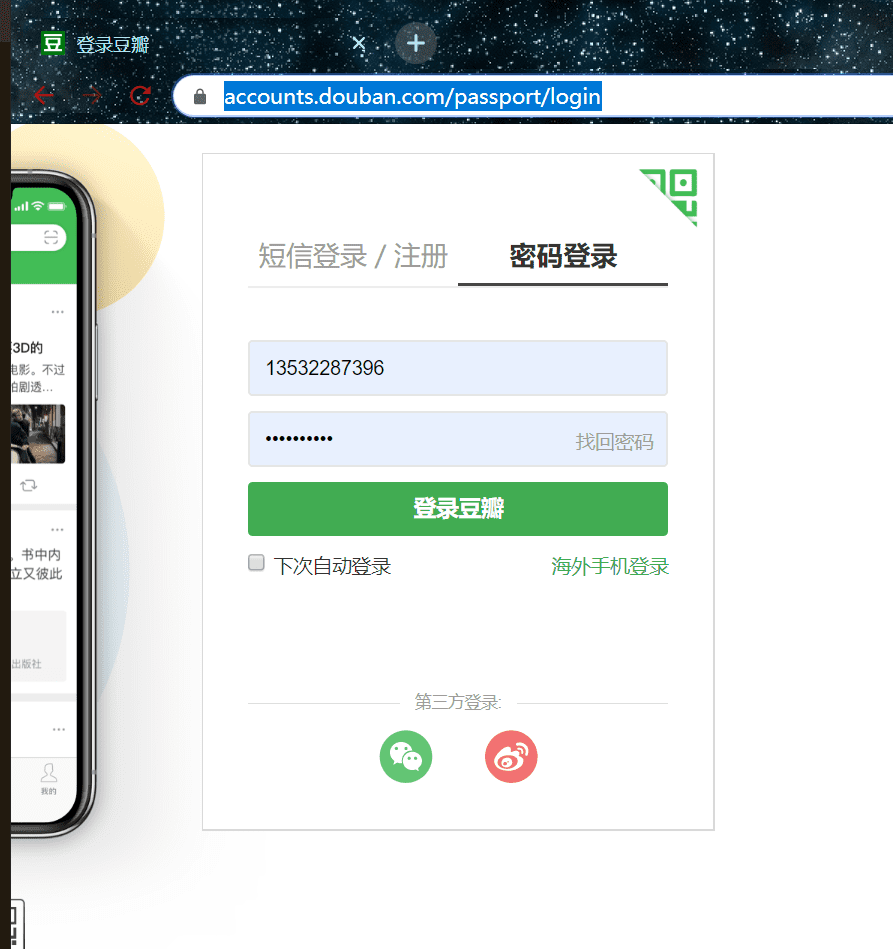
我们以登录豆瓣为例
https://accounts.douban.com/passport/login
流程
在人为登录时,我们选择使用【密码登录】
1、选中用户名,点击
2、输入用户名
3、选中密码框,点击
4、输入密码
5、点击登录
然后就会页面跳转到登录后的页面,我们前面讲了 selenium 就是模拟人的行为,所以流程就如上面一样的,代码仅仅用上一章的知识就够了,直接贴代码了
from selenium import webdriver
from selenium.webdriver.common.by import By #用于指定 HTML 文件中 DOM 标签元素
from selenium.webdriver.support.ui import WebDriverWait #等待网页加载完成
from selenium.webdriver.support import expected_conditions as EC #指定等待网页加载结束条件
url = 'https://accounts.douban.com/passport/login'
# 实例化浏览器
broswer = webdriver.Chrome()
# 打开网页
broswer.get(url)
# 等待账户输入框元素出现
WebDriverWait(broswer,10).until(EC.presence_of_element_located((By.CLASS_NAME,'account-form')))
# 点击选择【密码登录】
pwd_login = broswer.find_element_by_xpath('//ul[@class="tab-start"]/li[2]').click()
# 定位账户,密码框
user = broswer.find_element_by_xpath('//input[@id="username"]')
pwd = broswer.find_element_by_xpath('//input[@id="password"]')
# 输入账户密码
user.click()
user.send_keys('你的账户')
pwd.click()
pwd.send_keys('你的密码')
# 找到登录按钮,点击【登录】
login = broswer.find_element_by_xpath('//a[@class="btn btn-account btn-active"]').click()
END
登录后:
登录后,提取数据就可以用 selenim 的方法,也可以获取源码后用 bs4,正则,xpath
